
In spite of its young age, the Big Data ecosystem already contains a plethora of complex and diverse open source frameworks. They are commonly of two kinds: data platform frameworks, which deal with the needed storage scalability, or processing frameworks, which aim to improve query performance [1]. A Big Data application is generally produced by combining them in a smooth way. Each framework operates with its own computational model. For example, a data platform framework may manage distributed files, tuples, or graphs, and a processing framework may handle batch or real-time jobs. Building a reliable and robust Data-Intensive Application (DIA) consists in finding a suitable combination that meet requirements. Besides, without a careful design by developers on the one hand, and an optimal configuration of frameworks by operators on the other hand, the quality of the DIA cannot be guaranteed.
In this blog post we would like to mention three simple principles we have learned while we were building our Big Data application:
- Using models to synchronize the work of developers and operators;
- Designing databases so that we do not need to update or delete data; and
- Letting operators resolve low-level production-specific issues.
1. Synchronizing Developers and Operators Through Models
In a DevOps process, developers build and test the application in an isolated, so-called, development environment, while operators are in control of its targeted run-time environment — the production environment. Conceptually, the latter comprises all entities that will interact with the programme: infrastructures, operating systems, Web servers, software agents, individuals, and so on. It is the responsibility of operators to guarantee that every framework needed by the data-intensive application is installed in the production environment and properly configured.
Requirements cannot be meet without the joint contribution of developers and operators. Indeed, even if it is well programmed, a DIA may fail to reach its functional or non-functional goals due to failures, problems, or incorrect behaviors occurring in the production environment. The core idea of DevOps is to foster a close cooperation between the two teams and to keep them on the same page. We have learned to synchronize them through UML models. They serve as contracts where every expected aspects of the production environment are clarified and specified. We have designed stereotyped UML class and deployment diagrams for this purpose [3]. If the models are precise enough, it is even possible to install and configure automatically every framework.
However, effective communications between developers and operators are not enough to succeed in a Big Data project. One should also well organize the database. In the next section, we will explain a useful hint called immutability.
2. Achieving Fault-tolerance with Immutability
Applications should take into account that human faults are inevitable, that is, they should be carefully designed to limit the damage humans may cause. This is especially true with Big Data, which add many complexities to software construction, and where inaccuracies of data lead to fallacious decisions. A reliable Big Data system correctly answers any query at any time. When someone injects wrong data into it, it must preserve good data, and be able to infer and recover from erroneous piece of information subsequently.
In this section, we present a design principle we have learned from our experiment with Apache Cassandra [5] to achieve resilience: Immutability. The idea behind this concept is to never update data, we instead contextualize them (store the precise context with the data) so that they remain eternally true for different contexts. Let us take a basic example dealing with a customers’ database. We may consider the schema shown in the Table 1, in which each customer is identified by an ID, a name and an address.
Table 1: Initial customers’ database.
| Customer ID | Name | Address |
|---|---|---|
| 1 | Nicolas | Nice |
| 2 | Marc | Bordeaux |
| 3 | John | Paris |
Let us imagine that John (line 4 of the Table 1) moves to another city (e.g. Marseille). Our database will be updated accordingly and will look like the Table 2.
Table 2: Modified customers’ database.
| Customer ID | Name | Address |
|---|---|---|
| 1 | Nicolas | Nice |
| 2 | Marc | Bordeaux |
| 3 | John | Marseille |
This update process is correct from the point of view of the user because it is true, but it has 2 disadvantages. First, the historical data are lost, we don’t know anymore that John lived in Paris. Second, if this update was made by mistake, we introduce wrong data and get corrupted database. In our example, the information is simple and can be manually recovered. However, in a real application dealing with millions of inputs processed automatically using batch scheduling, the corruption of the database will be huge enough to kill the whole system.
This example may occur not only in a classical relational database but also with Big Data technologies. And because the data can be modified, i.e., the databases are mutable, they are not human fault-tolerant. The point here is not to confuse what the Big Data technologies manage for the designer and what the latter must consider while modeling/designing a DIA. For example, NoSQL databases like Apache Cassandra offer more scalability mainly thanks to the data modeling approach which must be thought out according to the way you will be querying your database but as we have seen, we are not away from a human error.
If we consider that we are no more allowed to modify (no update and delete) the data, the only authorized action is to add data: the data become immutable. If we consider our example, the relocation of John will not be processed as above but we will add the new information: John’s current address is Marseille. In order to be able to perform this, we will split our table in 2 separate tables (see Table 3).
Table 3: Human fault-tolerant customers’ database.
| Customer ID | Name |
|---|---|
| 1 | Nicolas |
| 2 | Marc |
| 3 | John |
| Customer ID | Address | Timestamp |
|---|---|---|
| 1 | Nice | 02/01/2012 14:23:56 |
| 2 | Bordeaux | 01/01/2008 08:00:01 |
| 3 | Paris | 04/12/2015 12:32:56 |
| 3 | Marseille | 01/01/2016 10:18:05 |
The first table contains the ID and the name of each customer and the second table contains the ID and all the known addresses for each of them. We added a timestamp field in order to know when this information is true. By getting the most recent value (using the timestamp values), we are able to know the current location of John. In addition, we are now able to get all the historical information regarding John’s previous addresses.
he immutable schema makes obvious the reliability of the new designed system regarding any human mistake. With a mutable data model, an error can cause data to be lost, because values are actually overridden in the database. With an immutable data model, no data can be lost. If bad data is written, earlier (supposed to be good) data units still exist.
3. Overcoming Operations’ Challenges
The Big Data paradigm shift has brought to light the quality attribute of resilience. A Big Data application is resilient when it is able to withstand or recover quickly from difficult conditions. If possible, it must continue to fulfil its assigned work effectively and efficiently whatever troubles its run-time environment may engender. Examples of issues include: network failures, losses of cluster nodes, memory shortages, high CPU load, reception of incorrect data, and so on [6]. These problems always originate from the environment and never from the application itself. Although they are, of course, all important to address, difficulties provoked by humans, purposely or not, are probably the worse. Indeed, hardware failures are repairable, and software agents are recognizable. But human-computer interactions may create veritable headaches.
As described in the previous section, the design of the data model can have concrete impacts on the quality of the application, especially in terms of reliability. But Big Data frameworks are complex and unless you get hands on experience, tuning each chosen framework in order to guarantee a high quality of service (memory optimization, CPU load, cluster properties, and so on) needs to be performed by an expert. Without this fine tuning, the efforts made at the design level are worthless. In this section, we illustrate these operations challenges using a concrete example related to Apache Cassandra. In order to free up space and improve performance, Apache Cassandra launches an intensive/expensive operation called Compaction. During that time period the server places substantially higher demand on the CPU and disks, which dramatically lowers the performance of that machine. A careful (complicated) configuration is required in order to avoid problems or server lockups during compaction. The performance loss can cause cascading failure especially if too many nodes compact at the same time, the load they were supporting will have to be handled by other nodes in the cluster. This can potentially overload the rest of your cluster, causing total failure.
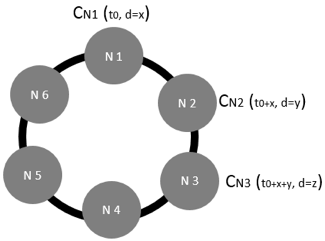
Figure 1. Compaction configuration.
Figure 1 shows a basic possible configuration where the compaction process for each node (CNx) must be scheduled in order to start after the previous node finished compacting. For instance, this configuration must take into account the duration (d) of the compaction process for each node.
As explained earlier this issue is one among many others which must be managed by the operations team. Unless a strong collaboration and communication strategy is built between the designers and the operators of the data-intensive application, it is impossible to take into account each specific technical requirement.
4. Conclusion
In this article, we provided a concrete example on the importance of the role of the developers and the operations in order to release reliable Big Data applications. We discussed the importance of both the data model design and the runtime platform configuration. DevOps provides a powerful set of principles and practices that help improve communication and collaboration between them. Delivering a reliable and fault-tolerant data-intensive application is only possible with the combination of knowledge, experience and specialized skills to deliver quality systems that delight the customers and ensure success and profitability.
Youssef Ridene and Joas Yannick KINOUANI
(Netfective Technology – https://www.bluage.com/)
References
- National Institute of Standards and Technology, NIST Big Data Interoperability Framework: Volume 2, Big Data Taxonomies, 2015.
- Nathan Marz and James Warren. Big Data Principles and best practices of scalable realtime data systems, Manning Publication, 2015.
- Abel Gómez, José Merseguer, Elisabetta Di Nitto, and Damian A. Tamburri. 2016. Towards a UML profile for data intensive applications. In Proceedings of the 2nd International Workshop on Quality-Aware DevOps (QUDOS 2016).
- Swain, A.D., Guttman, H.E. Handbook of human reliability analysis with emphasis on nuclear power plant applications. NUREG/CR-1278, Washington D.C., 1983.
- Eben Hewitt. Cassandra: The Definitive Guide, O’Reilly Media, 2010.
- Patra, Prasenjit Kumar; Singh, Harshpreet; Singh, Gurpreet. Fault Tolerance Techniques and Comparative Implementation in Cloud Computing. International Journal of Computer Applications, 2013.
Sorry, the comment form is closed at this time.