
As it is widely known, especially in the media industry, messages posted in social media contain valuable information related to events and trends in the real world. Various industries and brands that analyze social media are gaining valuable insights and information which they use in a number of operations.
For example, in the news industry, trend detection is useful for:
- identifying emerging news based on the popularity of a certain topic and
- defining areas of great public interest that should be closely monitored as even a small development affects many people and leads to emerging news.
As another example, in the financial sector, trends may have both short-term and long-term consequences, affecting from the daily price of stock to a country’s macroeconomic indicator. As an example, a trend demanding military action in the Middle East as a result of a terrorist attack may affect oil prices and subsequently decrease car sales.
To this end, and taking into account the large scale of that type of content, it is essential to develop methods for efficient trend detection in real-time.
For example, in recent years the pace of decision-making in breaking-news journalism has significantly increased. This is due to the multiplication of digital sources and incoming data streams, digital production processes, automation, real-time publishing and largely mobile news audiences.
The Storm topology in the following figure is a first sketch for the implementation of a known trend detection method in a distributed manner. The method is a feature-pivot method that analyzes the temporal distributions of words and discovers trends by grouping trending keywords together.
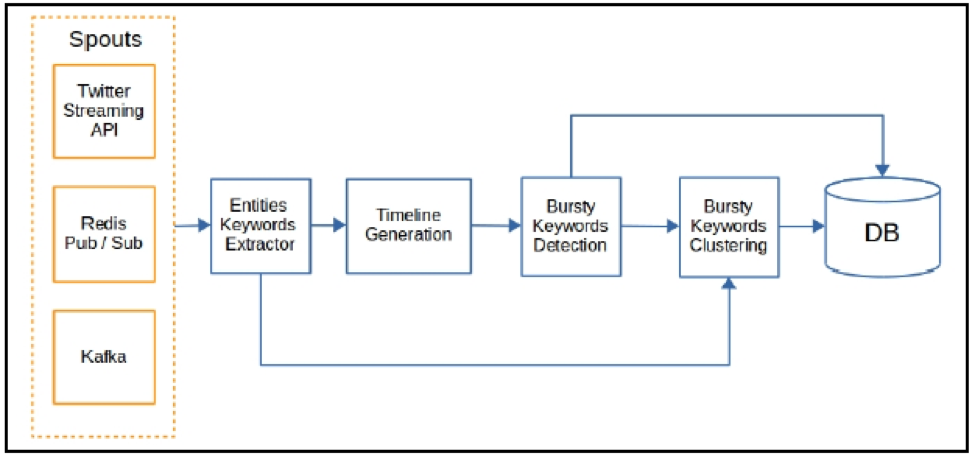
There are different possible inputs to the topology: Candidate spouts include the Twitter streaming API and queues that inject messages into the topology (Redis, Apache Kafka). The first processing bolt is responsible for the extraction of entities and keywords from the incoming messages.
Trivial keywords (e.g. stop-words) are discarded while the rest of them are forwarded to the next bolt. The Timeline Generation bolt aggregates tuples of keywords –timestamps and creates a set of statistics for each keyword. In other words, this bolt calculates a background model of expected frequencies based on historical data. Tuples associated with the same keywords are aggregated in the same worker of the Timeline Generation bolt in a similar fashion as in map-reduce.
The resulting baseline model is forwarded to the next bolt each time there is an update. Then, the Bursty Keywords Detection bolt compares current frequencies to the baseline model and detects keywords, for which their difference is extraordinary.
Finally, the detected bursty keywords are clustered together in the final bolt of the topology based on keywords co-occurrences. The extracted trends are stored in a database.
We are currently conducting experiments on this Trend Detector topology and trying out changes that may improve the quality of results.
Vasilis Papanikolaou, ATC
Symeon (Akis) Papadopoulos, CERTH-ITI
Sorry, the comment form is closed at this time.