
Many analysts point out that we are experiencing years in which technologies and methodologies that fall within the sphere of Big Data have swiftly pervaded and revolutionized many sectors of industry and economy, becoming one of the primary facilitators of competitiveness and innovation. IDC reported that the Big Data market will grow from $150.8 billion in 2017 to $210 billion in 2020, with a compound annual growth rate of 11.9%. Among the enabling technologies, Apache Hadoop was the first successful data-intensive framework, but its predominant market share is declining in favor of newer projects, such as Apache Spark.
In spite of the mentioned points in favor of Big Data technologies, fully embracing them is a very complex and multifaceted process. This is why many companies have started offering Cloud-based Big Data solutions (like Microsoft HDInsight, Amazon Elastic MapReduce, or Google Cloud Dataproc) and IDC expects that nearly 40% of Big Data analyses will be supported by public Clouds by 2020. The advantages of this approach are manifold. Yet, provisioning workloads in a public Cloud environment entails several challenges. In particular, the space of configurations can be very large, hence identifying the exact cluster configuration is a demanding task, especially in the light of the consideration that the blend of job classes in a specific workload and their resource requirements may also be time-variant.
This work addresses the problem of rightsizing Apache Hadoop and Spark clusters, deployed in the Cloud and supporting different job classes while guaranteeing the quality of service (QoS). Each class is associated with a given concurrency level and a deadline, meaning that several similar jobs have to run on the cluster at the same time without exceeding a constraint imposed on their execution times. Additionally, the cluster can exploit the flexibility of Cloud infrastructures by adopting different types of virtual machines (VMs), taking into account performance characteristics and pricing policies.
The capacity planning problem is formulated by means of a mathematical model, with the aim of minimizing the cost of Cloud resources. The problem considers several VM types as candidates to support the execution of DIAs from multiple user classes. Given the complexity of virtualized systems and the multiple bottleneck switches that occur in executing DIAs, very often the largest available VM is not the best choice from either the performance or performance/cost ratio perspective. Through a search space exploration, the proposed approach seeks the optimal VM type and number of nodes, considering also specific Cloud provider pricing models. The underlying optimization problem is NP-hard and is tackled by a simulation-optimization procedure able to determine an optimized configuration for a cluster managed by the YARN Capacity Scheduler. DIA execution times are estimated by relying on multiple models, including machine learning (ML) and simulation based on queueing networks (QNs), stochastic Petri nets (SPNs. This research led to the development of D-SPACE4Cloud, a software tool, integrated within the DICE IDE, designed to help system administrators and operators in the capacity planning of shared Big Data clusters hosted in the Cloud to support both batch and interactive applications with deadline guarantees.
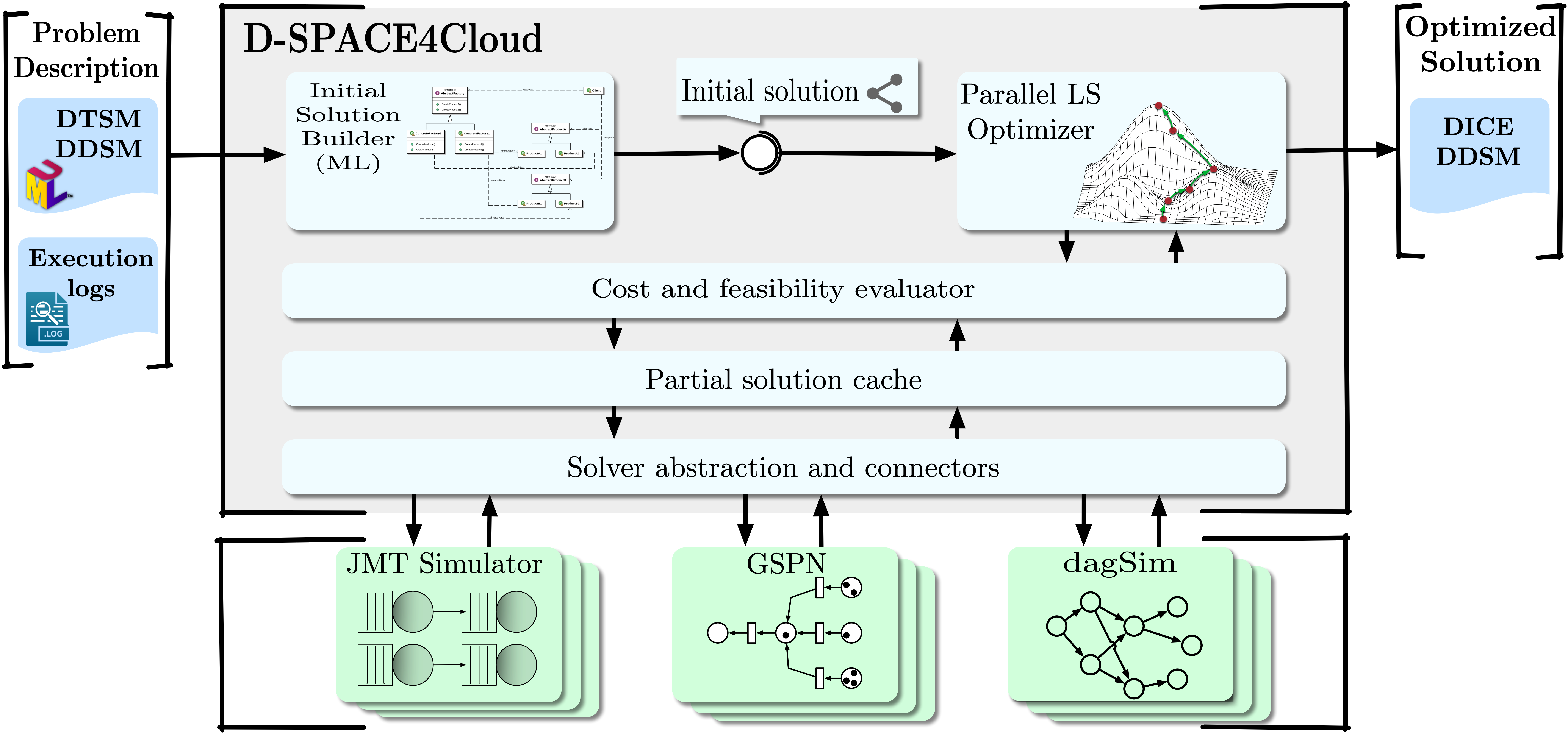
Figure 1: D-SPACE4Cloud architecture.
Extensive validation results obtained on a gamut of real deployments corroborate D-SPACE4Cloud’s quality. The experiments are based on the TPC-DS industry standard benchmark for business intelligence data warehouse applications. Microsoft Azure HDInsight, Amazon EC2, the CINECA Italian supercomputing center, and an in-house cluster with IBM POWER8 processors have been considered as target deployments. The proposed approach proved to achieve good performance across all these alternatives, despite their peculiarities. Simulation results and experiments performed on real systems have shown that the achieved percentage error is within 30% of the measurements in the very worst case. On top of this, it is shown that optimizing the resource allocation, in terms of both type and number of VMs, offers savings up to 20–30% in comparison with the second best configuration. In particular, at times, general purpose instances turned out to be a better alternative than VMs advertised as suitable for Big Data workloads.
Further details can be found in the paper bound for publication in IEEE Transactions on Cloud Computing, 10.1109/TCC.2018.2874944.
Eugenio Gianniti, Politecnico di Milano
Michele Ciavotta, Politecnico di Milano
Danilo Ardagna, Politecnico di Milano
Sorry, the comment form is closed at this time.