
Big Data systems are regarded as a new class of software systems leveraging several emerging technologies to efficiently ingest, process and produce large quantities of data. Each of the comprising technologies (e.g., Hadoop, Spark, Cassandra) has typically dozens of configurable parameters that should be carefully tuned in order to perform optimally. Unfortunately, users of such systems, like data scientists, usually lack the technical skills to tune system internals. Such users would rather use a system that can tune itself. Yet, there is a shortage of automated methods to support the configuration of Big Data systems. One possible explanation is that the influences of a configuration option on performance are not well understood [1].
Performance differences between a well-tuned configuration and a poorly configured one can be of orders of magnitude. Typically, administrators use a mix of rules-of-thumb, trial-and-error, and heuristic methods for setting configuration parameters. However, this way of testing and tuning is slow, and requires skillful administrators with a good understanding of the system internals. Furthermore, decisions are also affected by the nonlinear interactions between configuration parameters.
Today’s mandate for faster business innovation, faster response to changes in the market, and faster development of new products demand a new paradigm for Big Data software development. DevOps [2] is a set of practices that aim to decrease the time between changing a system in Development, and transferring the change to the Operation environment, and exploiting the Operation data back in the Development. Continuous Configuration Optimization is one of the cornerstone practices in DevOps where the tuning process require Ops data in order to optimize the performance of Dev [3].
We have developed a Configuration Optimization Tool for Big Data Systems called BO4CO. Bayesian Optimization for Configuration Optimization (BO4CO) [1] is an auto-tuning algorithm for Big Data applications. BO4CO helps end users of big data systems such as data scientists or SMEs to automatically tune the system.
The following figure illustrates components of BO4CO: (i) optimization component, (ii) experimental suite, (iii) and a data broker.
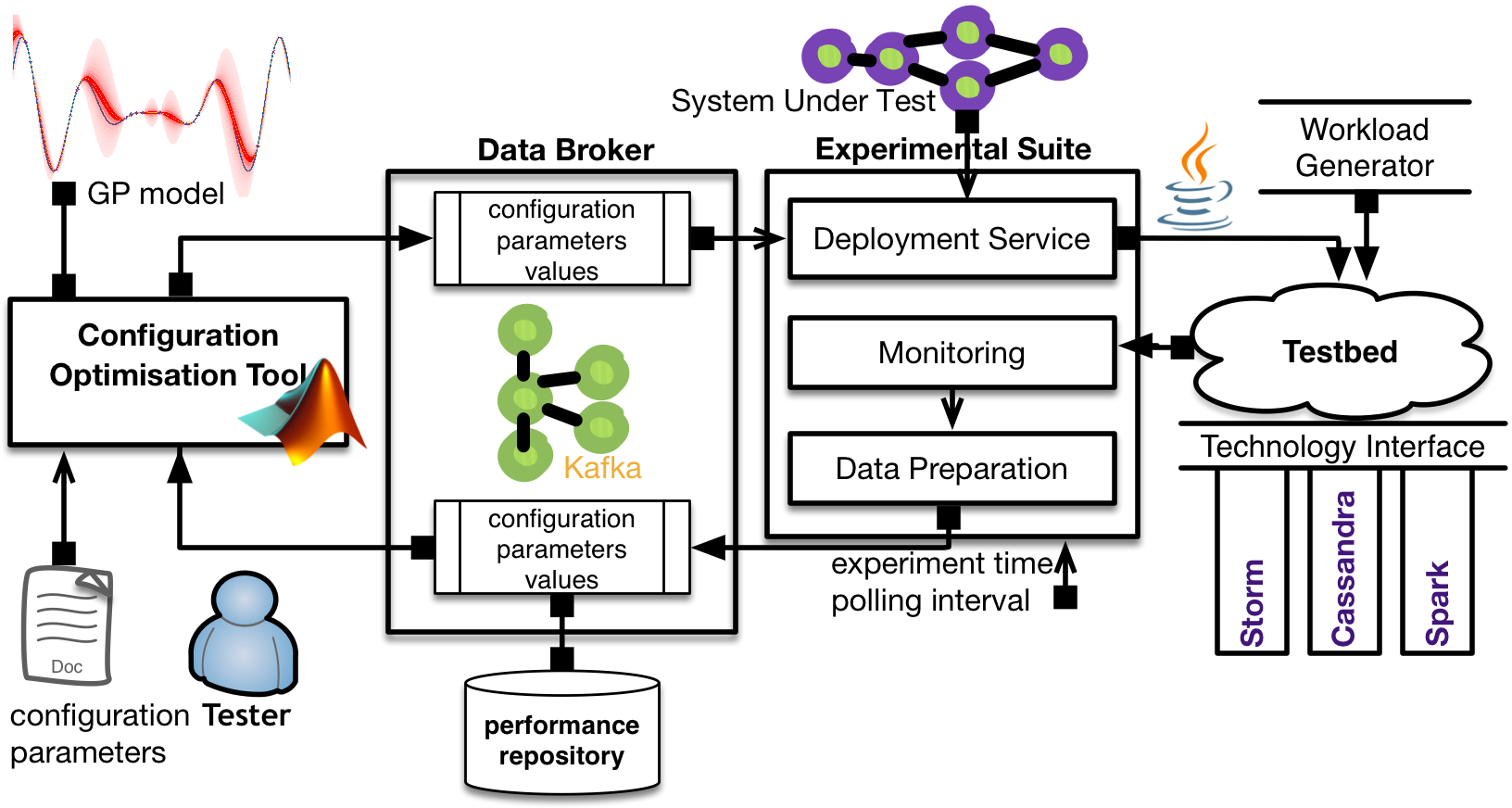
Figure 1. BO4CO Architecture [1].
BO4CO is designed keeping in mind the limitations of sparse sampling from the configuration space. For example, its features include: (i) sequential planning to perform experiments that ensure coverage of the most promising zones; (ii) memorization of past-collected samples while planning new experiments; (iii) guarantees that optimal configurations will be eventually discovered by the algorithm.
We have carried out extensive experiments with three different stream processing system benchmarks running on Apache Storm. The experimental results demonstrate that BO4CO outperforms the baselines in terms of distance to the optimum performance with at least an order of magnitude. We have also provided some evidence that the learned model throughout the search process can be also useful for performance predictions. For more information regarding the experimental results, please refer to [1].
BO4CO is integrated with DICE delivery tools (Deployment Service and Continuous Integration), DICE monitoring platform (D-Mon) as well as DICE IDE. BO4CO currently supports Apache Storm and Cassandra. We will extend this technology support to Apache Spark and Hadoop in the next release. The integration with DICE quality testing is also under way. We are also developing a novel approach that takes into account previous system measurements in order to accelerate the tuning process. This approach is suitable in DevOps context where several system versions are continuously released on daily basis.
You can either use BO4CO as a stand-alone application which only require royalty free MATLAB runtime (MCR) to optimize your big data application, or as an integrated solution alongside other DICE DevOps tools. For more details about BO4CO please visit its Github page.
Pooyan Jamshidi (IMP)
References
[1] P. Jamshidi, G. Casale, “An Uncertainty-Aware Approach to Optimal Configuration of Stream Processing Systems“, in Proc. of IEEE MASCOTS, 2016.
[2] A. Balalaie, A. Heydarnoori, P. Jamshidi, “Microservices Architecture Enables DevOps: Migration to a Cloud-Native Architecture“, IEEE Software, Vol. 33, Issue 3, pp. 42-52, 2016.
[3] E. Di Nitto, P.Jamshidi, M. Guerriero, M. Guerriero, I. Spais, D. A. Tamburri, “A Software Architecture Framework for Quality-Aware DevOps“, in Proc. of QUDOS, 2016.
Complementary materials
- Paper is the key paper about BO4CO.
- Wiki provides more details about the tool and setting up the environment.
- Data is the experimental datasets.
- Presentation is a presentation about the tool and our experimental results.
- Gitxiv is all research materials about the tool in one link.
- TL4CO is the DevOps enabled configuration optimization tool.
Sorry, the comment form is closed at this time.